Neural Net Model Comparisons
This is a continuation of my last post on building a web scaper to use with TensorFlow Playground. I described how I wrote the code for my web scraper using Selenium, so I could run trials with different conditions for different configurations and saving the results.
Below is a table of the data I collected for the MYBEST model with my assessments on it’s success for each trial. To judge for success the test loss was compared against 0.15 where test loss values below 0.15 were considered a success and all others were failures. For determining overfit, if the test loss was more than 0.1 larger than the training loss, I classified it as an overfitted model.
| Model | Problem | Quality | Outcome | Overfit? | Time Taken | Training Loss | Test Loss |
|---|---|---|---|---|---|---|---|
| MYBEST | gauss | Q-BEST | Success | no | 3.761389970779419 | 0.001 | 0.001 |
| MYBEST | xor | Q-BEST | Success | no | 3.7923269271850586 | 0.002 | 0.004 |
| MYBEST | circle | Q-BEST | Success | no | 3.792457103729248 | 0.004 | 0.004 |
| MYBEST | spiral | Q-BEST | Failure | yes | 30 | 0.352 | 0.494 |
| MYBEST | reg-plane | Q-BEST | Success | no | 1.3344132900238037 | 0 | 0 |
| MYBEST | reg-gauss | Q-BEST | Success | no | 13.540304899215698 | 0.021 | 0.027 |
| MYBEST | gauss | Q-WORST | Success | no | 30 | 0.101 | 0.144 |
| MYBEST | xor | Q-WORST | Failure | yes | 30 | 0.173 | 0.285 |
| MYBEST | circle | Q-WORST | Failure | yes | 30 | 0.288 | 0.419 |
| MYBEST | spiral | Q-WORST | Failure | no | 30 | 0.458 | 0.503 |
| MYBEST | reg-plane | Q-WORST | Success | no | 6.101944446563721 | 0.026 | 0.032 |
| MYBEST | reg-gauss | Q-WORST | Success | no | 6.143972158432007 | 0.037 | 0.043 |
| MYBEST | gauss | Q-OK | Success | no | 6.140700101852417 | 0.016 | 0.038 |
| MYBEST | xor | Q-OK | Success | no | 11.003361701965332 | 0.068 | 0.066 |
| MYBEST | circle | Q-OK | Success | no | 8.588461161 | 0.074 | 0.084 |
| MYBEST | spiral | Q-OK | Failure | no | 30 | 0.414 | 0.5 |
| MYBEST | reg-plane | Q-OK | Success | no | 6.335601568222046 | 0.005 | 0.005 |
| MYBEST | reg-gauss | Q-OK | Success | no | 23.513009309768677 | 0.027 | 0.031 |
The models were successful at solving all the regression problems. However, none of the models were able to solve all the data sets since none of the models were able to successfully solve the spiral. The spiral was the hardest data set with circle and then exclusive or as the next hardest data sets to solve. There were no obvious patterns in the qualities leading to performance. MYBEST had the lowest average test loss among the models and had a higher count of successes. There are general observations, but no hard rules. In general, the top performing successful test losses had 2 hidden layers.
Further Comparisons
I did tests with a new model which I dubbed DNN to be my version of a deep neural net. The configuration is as shown below.
- activation = relu
- networkShape = 5,5,5
- x and y inputs
I ran some more trials with this model and with the MYBEST model looking at the classification problem using the spiral dataset since that is the one that seemed to be the most difficult for each model. I looked at is how they compared in performance with different amounts of noise across increasing percentages of training data. Below are some rough graphs I made using Excel to compare the two models with 9 trials for each model for 0 percent noise and 30 percent noise.
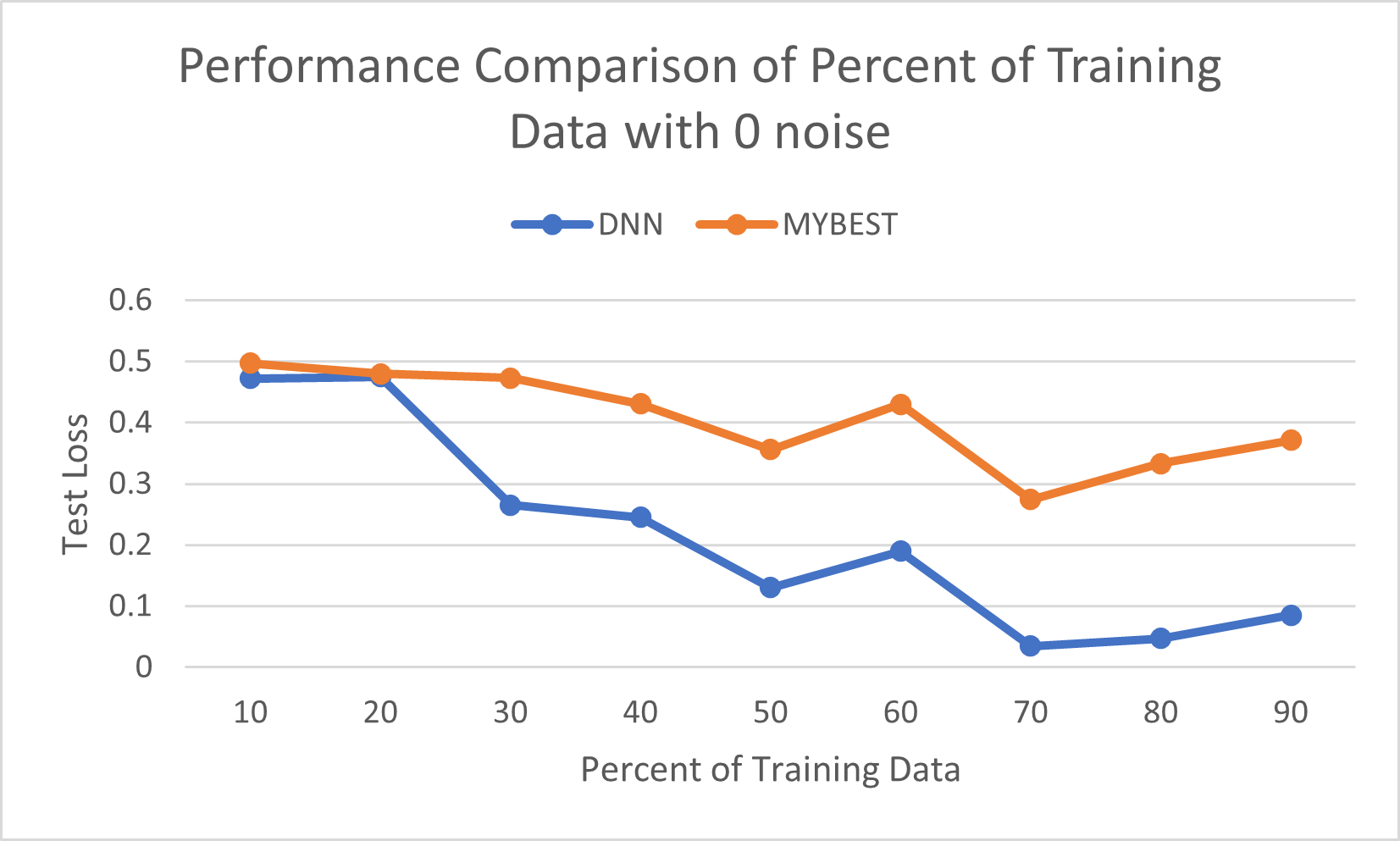
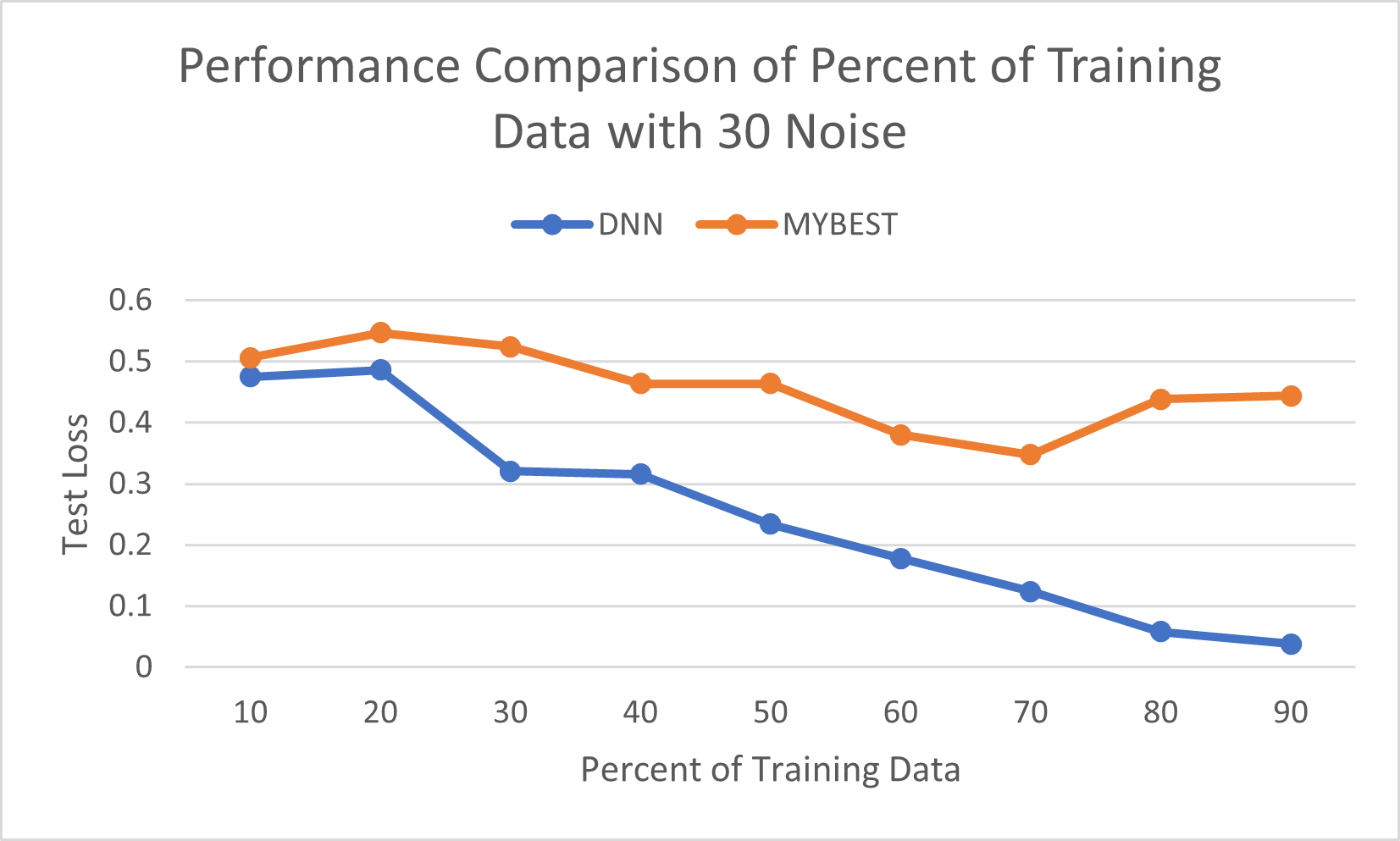
The DNN model performed better than the MYBEST model in every condition. Very ironic considering the model is named “MYBEST” and yet it was not very good.